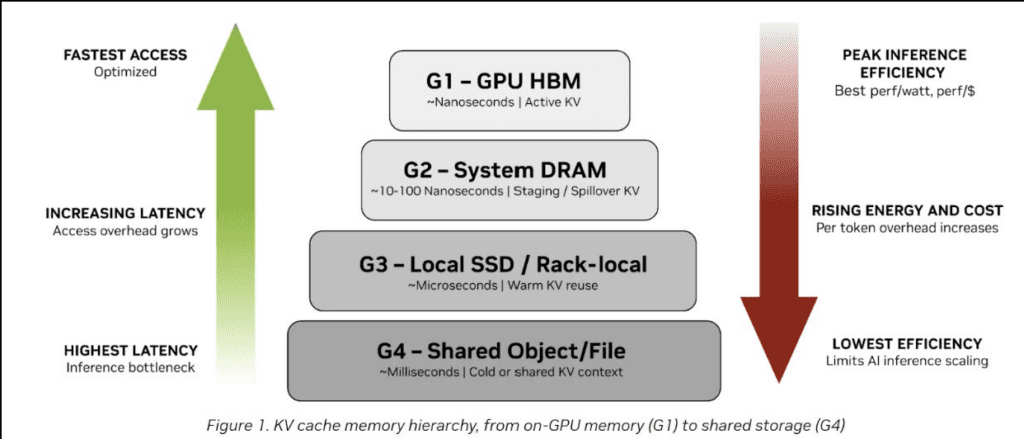
GPUs are no longer the bottleneck. Data movement is.
I recently attended an online talk that stayed with me longer than most.
Not because of a new GPU announcement, but because it clearly articulated something I have seen repeatedly over the years, across very different systems.
That message, strongly emphasized by Jensen Huang, can be summarized in one sentence.
“The bottleneck is no longer compute.
The bottleneck is data movement.”
This resonates deeply with my own path, from HPC to Big Data and now large-scale DevOps and infrastructure.

A familiar lesson from HPC
I started my career in numerical optimization and HPC.
Back then, it was already obvious that raw compute power alone did not guarantee performance.
If memory, storage, and interconnects were not balanced, the system stalled.
Adding more cores only made the imbalance more visible.
Years later, when I moved from physics into Big Data, I faced a choice.
Focus on models and data science, or focus on distributed systems and storage.
I chose systems and storage, because that was where global performance was decided.
With hindsight, that choice feels even more relevant today.
GPUs changed scale, not the rules
GPUs have changed the scale of what is possible.
They did not change the fundamental rules of systems engineering.
Modern GPUs are no longer simple accelerators.
They sit at the center of the system and pull data at extreme rates.
When everything works, the gains are spectacular.
When data paths fall behind, GPUs wait.
This is exactly what we now observe in many AI platforms.
Large context windows make the problem worse
Recent analysis and benchmarks shared by WEKA highlight an important shift in inference workloads.
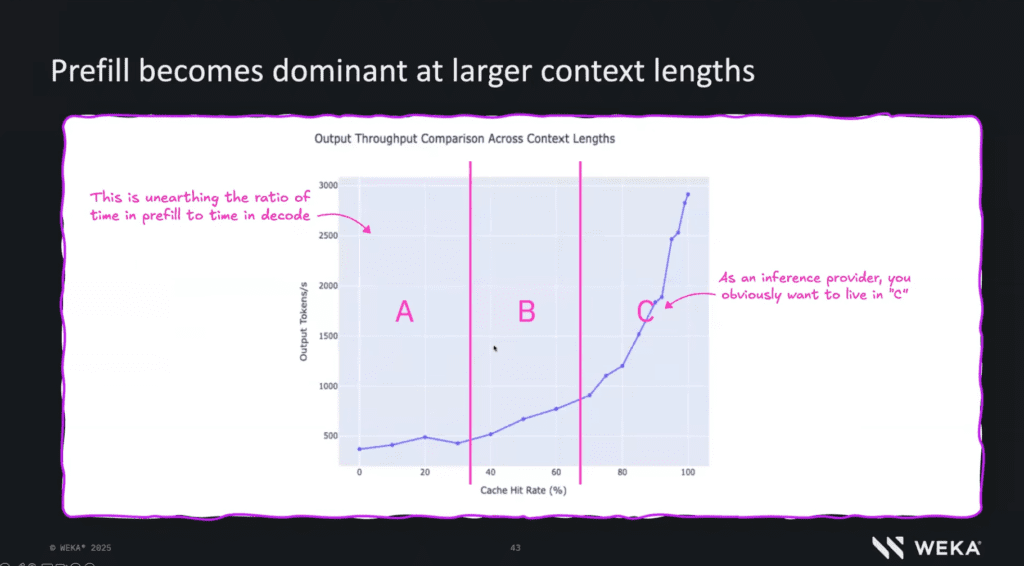
As context windows grow, prefill increasingly dominates decode.
This means a much larger amount of data must be accessed before token generation even begins.
Two consequences follow:
- storage bandwidth becomes critical
- latency becomes extremely sensitive to cache behavior
At large context sizes, inference is no longer compute-bound.
It is bound by how efficiently data can be fetched and reused.
Cache hit rate becomes the key metric
One of the most striking insights from WEKA’s data is the relationship between cache hit rate and throughput.
When cache hit rates are low or unstable:
- throughput collapses
- latency spikes appear
- GPU utilization drops sharply
When cache hit rates are high and stable:
- throughput increases dramatically
- latency becomes predictable
- the system operates in a different performance regime
For an inference provider, this difference is existential.
You want to operate in the high hit rate regime at all times.
This is not a model issue.
It is a storage and caching issue.
Where caching inefficiencies come from
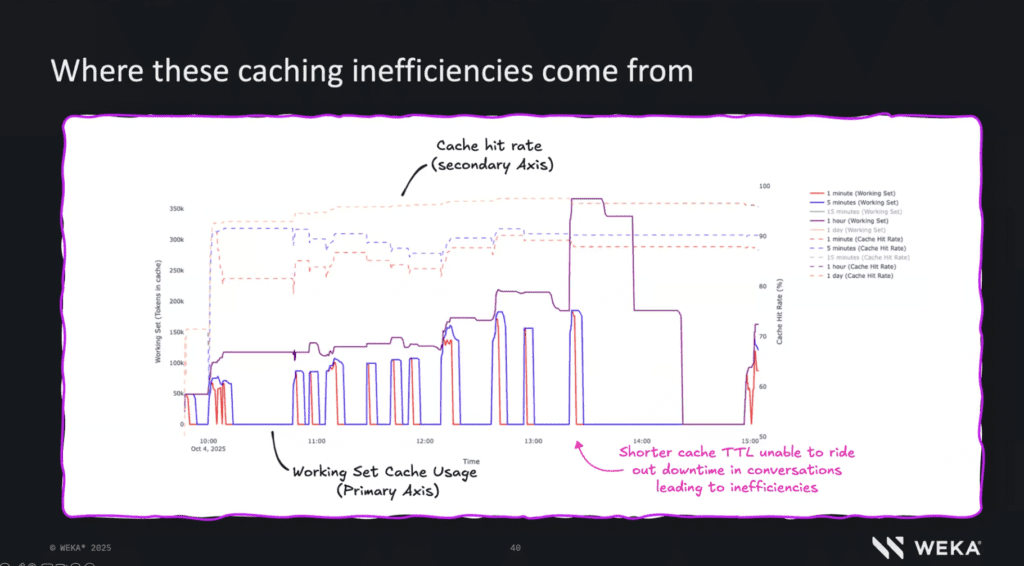
Another important point illustrated by WEKA is that cache inefficiencies are often structural.
Inference traffic is bursty.
Conversations pause.
Working sets evolve over time.
If cache TTLs are too short, caches empty during idle periods.
When traffic resumes, cache hit rates drop and latency jumps.
As context windows grow, working sets grow with them.
Short-lived caches are no longer sufficient.
This has nothing to do with GPU performance.
It is a consequence of storage systems not being designed for large, persistent working sets with high reuse.
The real infrastructure consequence
Larger context windows require more storage.
Not just more capacity, but storage designed for predictable, high-bandwidth access and efficient caching.
If cache hit rates are not optimized:
- latency becomes unstable
- GPUs stall
- inference costs rise silently
From the outside, this often looks like a software or model issue.
In reality, it is almost always a system design problem.
A personal conclusion
After more than fifteen years working on large-scale systems, one conviction has only grown stronger.
The biggest performance gains rarely come from better models.
They come from better data movement.
This was true in HPC.
It was true in Big Data.
It is now impossible to ignore in AI.
That is why Jensen Huang’s message matters.
And that is why the data shared by WEKA is so valuable. It makes the problem measurable.
Final thought
We spend a lot of time talking about models, frameworks, and GPUs.
In real production systems, compute is rarely the limiting factor.
Data paths almost always are.
That is where AI platforms either scale cleanly or quietly fail.
Video that triggered this reflection:
https://www.youtube.com/watch?v=o-etY6VLHZo
Credit
The cache behavior, prefill dominance, and inference insights discussed here are based on analysis and material published by WEKA.
See it on Linkedin


0 Comments