When Tesla published patent WO2024073080 describing a new file format internally called “.smol”, the headline was simple:
4x reduction in IOPS for AI training.
Most people read this as a hardware story.
It isn’t.
It’s a data architecture story.
And it exposes a structural weakness in how most enterprise data lakes are built today.
The Real Bottleneck in AI Infrastructure
In large-scale AI training systems, GPUs are rarely the limiting factor anymore.
The bottleneck is often:
- Data loading
- Storage layout
- CPU decode overhead
- Random access inefficiency
You can build the fastest GPU cluster in the world.
If your data format forces sequential scans and decoding overhead, you are burning millions in idle GPU time.
This phenomenon is known as data starvation.
And most enterprise architectures are built in a way that guarantees it.
Why Legacy File Formats Fail at Scale

Standard formats like:
- MP4
- CSV
- JSON
- even Parquet
were not designed for:
- High-frequency random sampling
- GPU-aligned tensor loading
- Deterministic byte-level access
- Massive parallel training clusters
Example 1 — Inter-frame video compression
MP4 is optimized for streaming.
If you need frame 50, you often need to decode frames 1–49 first.
For AI training, that’s wasted compute.
Example 2 — Text-based formats
CSV rows are variable-length.
You cannot jump directly to row 1,000,000.
You must scan 999,999 rows to find it.
That’s a parsing tax.
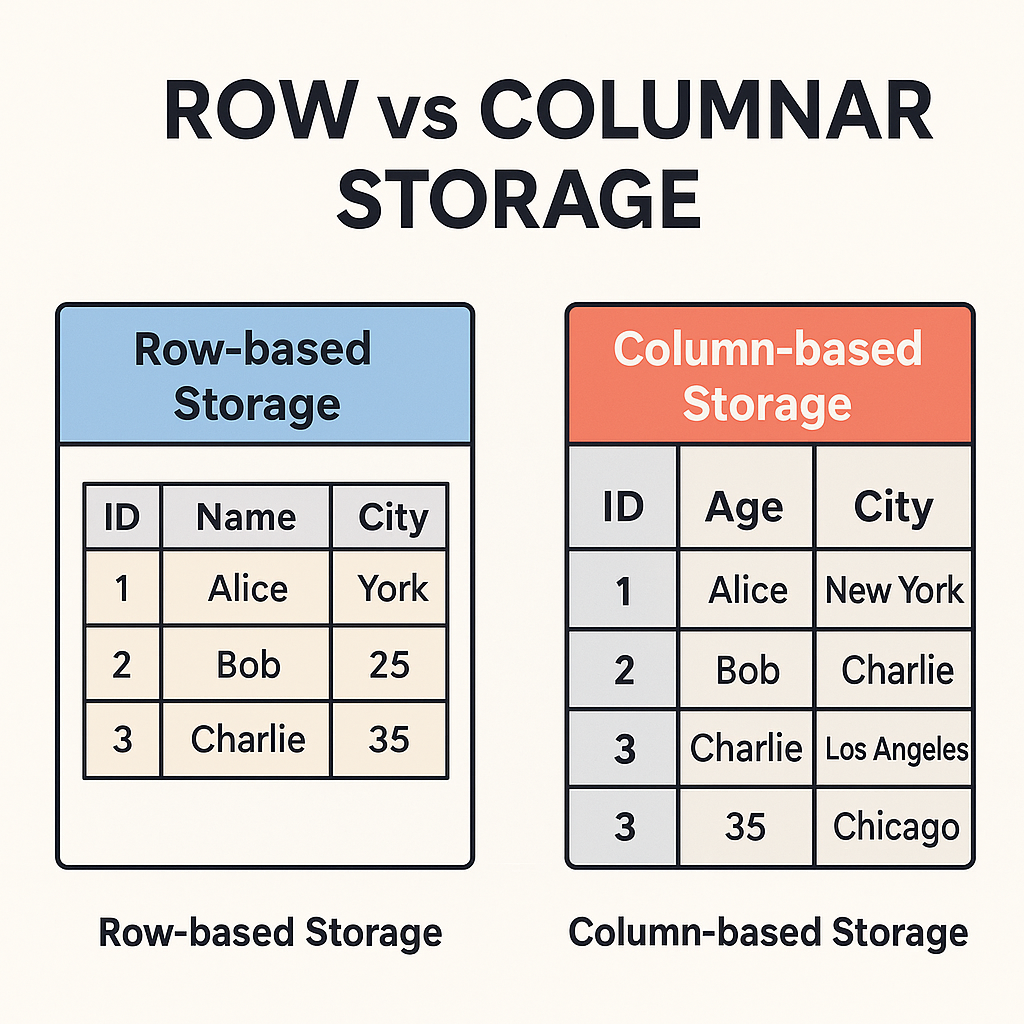
Example 3 — Even Parquet Isn’t Perfect
Parquet improves columnar access.
But:
- It is still file-based.
- It still assumes analytical batch workloads.
- It is not designed around tensor-native training loops.
Most enterprise data lakes are optimized for:
Storage cost + BI compatibility
Not:
Deterministic, GPU-saturating training pipelines
That’s the architectural mismatch.
What Tesla Changed
Tesla didn’t just optimize a format.
They changed the philosophy.
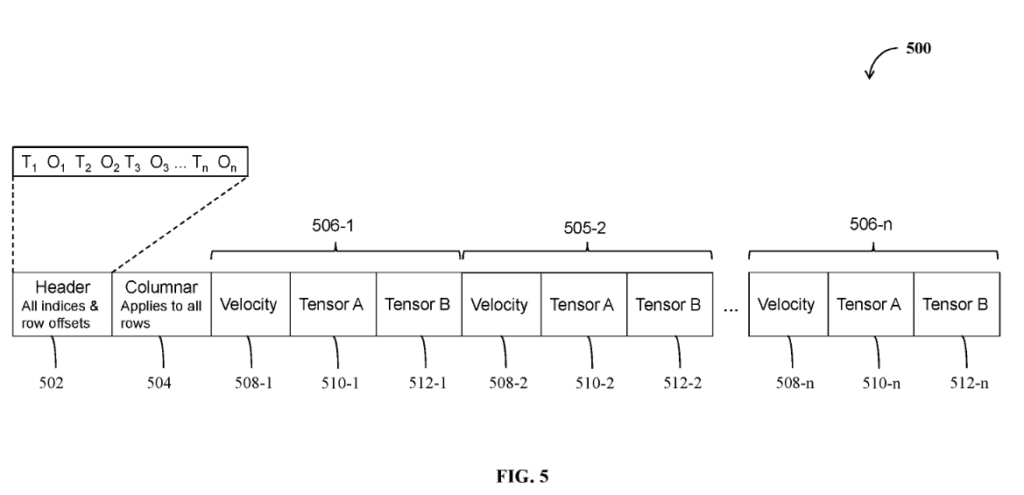
Key ideas behind .smol:
- Header-first master index
→ Every timestamp mapped to exact byte offset. - Deterministic random access
→ No scanning. No parsing. - Static vs dynamic segregation
→ No repeated metadata. - Column ordering by size
→ Early rejection possible. - Immutable layout
→ Index never invalidated. - Native tensor storage
→ No decode or transpose overhead.
This is not incremental optimization.
This is storage built for training loops, not humans.
Here’s the Uncomfortable Question for Enterprises
Most enterprise AI pipelines today look like this:
Object storage (S3-compatible)
- Parquet
- Iceberg/Delta
- Spark / PyTorch data loaders
- GPU cluster
On paper, this is modern.
But ask yourself:
- Are your GPUs ever waiting for data?
- How many small random reads per second are you doing?
- How much CPU time is spent decoding?
- Are you reading 2GB files to extract 100MB of useful tensors?
If the answer is “yes” to any of those…
Your architecture has a structural ceiling.
The Structural Problem of Enterprise Data Lakes
Enterprise data lakes were designed around:
- Analytical workloads
- Batch processing
- Schema evolution
- Governance
- BI tooling compatibility
They were not designed around:
- High-frequency tensor sampling
- Massive GPU parallelism
- Robotics-scale sensor ingestion
- Real-time retraining
We are trying to run AI-native workloads on analytics-native storage systems.
That mismatch is growing.
When Does This Actually Matter?
Let’s be rational.
For many companies, this does not matter.
It probably does NOT matter if:
- You train models once per month
- You have moderate GPU usage
- Your workloads are tabular
- You are CPU-bound
It starts to matter if:
- You iterate models daily
- You run multi-GPU clusters
- You use large vision or multimodal datasets
- You depend on random sampling
It becomes strategic if:
- You operate at multi-petabyte scale
- You run continuous retraining loops
- You ingest high-density sensor streams
- You compete on AI velocity
At that point, storage layout becomes a competitive advantage.
The Real Takeaway
Tesla didn’t invent a file format.
They exposed a shift:
AI systems are no longer limited by model design.
They are limited by data plumbing.
The next optimization frontier is not:
- better GPUs
- bigger clusters
It is:
- deterministic data layout
- IO-aware architecture
- tensor-native storage
- removal of CPU decode tax
In high-performance computing, this mindset is standard.
In enterprise data lakes, it is still rare.
That gap will close.
Final Thought
If your AI roadmap includes:
- computer vision
- multimodal AI
- robotics
- high-frequency experimentation
You may want to audit not just your models.
But your file formats.
Because your data lake might be the slowest component in your entire AI strategy.
Links:
– Patent
– source on X
– linkedin

0 Comments